Toggle navigation
Mr.Strawberry's House
文章
网址导航
更多
甜品站
杂物间
新版博客
关于 快刀切草莓君
友情链接
妙妙屋开发日志
注册
登录
搜索
文章列表
分类 标签
归档
# 基于图的异构外部知识的常识推理 Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering 本文提出了一种方法自动地从异构知识源抽取事实,并以此来回答问题。 [TOC] ## 1 Introduction 用了结构化知识库 ConceptNet 和自由文本 Wikipedia,根据两者来建图以获得 evidence 的关系结构。 <img src="https://i.loli.net/2021/02/01/BZEpUTonD2byhrl.png" alt="image-20210201161719641" style="zoom:67%;" /> **知识抽取模块** - 从 ConceptNet 中抽取图路径,从 Wikipedia 抽取句子。 - 为两个知识源构建图:cpnt 是本来的路径,wiki 是对句子 SRL 取得三元组。 **基于图的推理模块** - 基于图的**上下文词表示学习**模块:利用了图的结构知识,重定义了词语之间的距离。 - 应用了**图卷积网络**将邻接点信息编码到节点的表示。 - 用**图注意力机制**聚合 evidence 来预测最终的结果。 <img src="https://i.loli.net/2021/01/30/UckihuBr8YZfjOy.png" alt="image-20210130141414330" style="zoom:67%;" /> ## 2 Knowledge Extraction 根据给定的问题和选项从 ConceptNet 和 Wikipedia 中抽取 evidence ### 2.1 ConceptNet 三元组组成:2 node, 1 relation, 1 weight 搜索从问题实体到选择实体小于三跳的路径,将包含的三元组融合成 Concept-Graph。值得注意的是,图以三元组为节点,有关系的三元组之间连边。 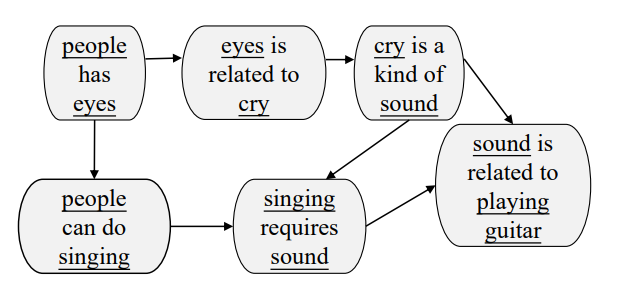 ### 2.2 Wikipedia 使用 Spacy 抽取了 107M 的 wikipedia 句子,应用 Elastic Search 来索引句子。(去停用词,拼接问题和选项作为 query) 构造 wiki-graph,利用SRL来抽取三元组(主语、谓语、宾语 subjective, predicate, objective),arguments 和 谓语作为图中的节点,`<subjective, predicate>` 和 `<predicate, objective>`作为边。 为了增加连接性,取出停用词并根据增强规则增加边:1.节点A被包括在节点B中,且A有超过三个词;2. 节点A和节点B只有一个不同的词,且A和B的单词数量都多于3 下图为根据 "He began making music when he started guitar lessons" 和 "Making music and playing guitar are his hobbies" 构造出来的图,虚线是用增强规则1 增加的边。 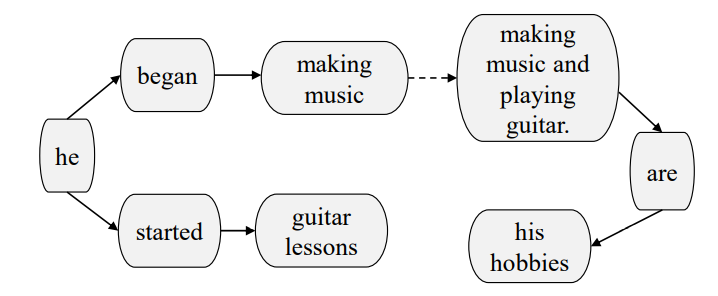 ## 3 Graph-Based Reasoning 包括:基于图的上下文词表示学习模块 和 基于图的推断模块,模型如下图所示。 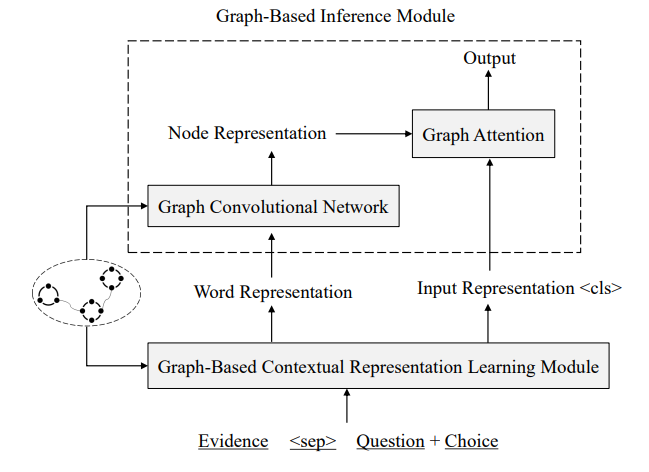 ### 3.1 Graph-Based Contextual Representation Learning Module 基于图的上下文表示学习模块 XLNEet,可以捕获长距离的依赖关系,获取每个词的表示的简单方法是拼接所有的 evidence 再输入到 XLNet,这个做法会使不同句子间语义相关的词距离很远。 使用图结构重新定义 evidence words 的相对位置 (relative postion) 可以使得语义相关的词有较短的相对距离,且 evidence 的内部关系结构也被用来获得更好的上下文词表示。 <img src="https://i.loli.net/2021/02/04/Q3SNF6mt1hoU4CX.png" alt="image-20210204100031646" style="zoom:67%;" /> ConceptNet 和 Wikipedia 构的图有分别对应的方法转换成自然语言形式,转换过程还进行了排序(算法如上图所示),使得相似的的三元组更靠近。 通过将抽取的图转换成自然语言形式,再喂入预训练模型,我们可以将两个不同的异构知识源融合到相同的表示空间。 ### 3.2 Graph-Based Inference Module 基于图的推断模块 预训练模型提供词级别的线索,图提供语义级别的信息,在图级别上聚合 evidence,来获得最终的预测。 将 Concept-Graph 和 Wiki-Graph 视为一张图,并应用图卷积网络来获取节点的表示来编码图结构的信息,为了缓解过参数化的问题,我们将图视为无向图。 第 i个节点的表示 $h_i^0$ 由相应 evidence 的 XLNet 输出的平均隐状态经非线性转换降维得到:$h_i^0=\sigma(W\sum_{w_j∈S_i}\frac{1}{|S_i|}h_{w_j})$,其中 $S_i={w_0,...,w_t}$是第i个节点 相关的 evidence, $h_{w_j}$ 是$w_j$上下文表示,$W∈R^{d×k}$。为了进行推理,用两步来传递 evidence:整合和连接。 第一步是聚合每个节点的邻居信息, $z_{i}^{l}=\sum_{j \in N_{i}} \frac{1}{\left|N_{i}\right|} V^{l} h_{j}^{l_{j}}$, $N_i$是第 i 个节点的邻居,$h_j^l$ 是第 l 层的第 j 个节点的表示;$h_{i}^{l+1}=\sigma\left(W^{l} h_{i}^{l}+z_{i}^{l}\right)$ 利用图注意力机制来聚合图级别的表示来进行预测,$\alpha_{i}=\frac{h^{c} \sigma\left(W_{1} h_{i}^{L}\right)}{\sum_{j \in N} h^{c} \sigma\left(W_{1} h_{j}^{L}\right)}$ ,$h^{g}=\sum_{j \in N} \alpha_{j}^{L} h_{j}^{L}$ ,其中 $h^c$ 是 CLS 的表示,$h^g$ 是图的表示。 将 $h^c$ 和 $h^g$ 拼接,过一个多层感知机来计算最后的分数,最后得到每个选项的概率 $p(q, a)=\frac{e^{s \operatorname{core}(q, a)}}{\sum_{a^{\prime} \in A} e^{\operatorname{score}\left(q, a^{\prime}\right)}}$,选择最高的来输出。 ## 4 Experiment 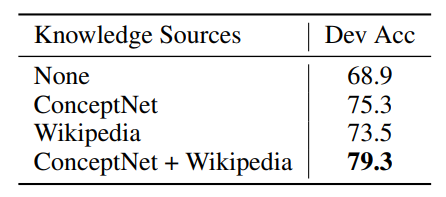
文章信息
标题:基于图的异构外部知识的常识推理
作者:快刀切草莓君
分类:自然语言处理
发布时间:2021年2月4日
最近编辑:2021年2月4日
浏览量:1363
↑