Toggle navigation
Mr.Strawberry's House
文章
网址导航
更多
甜品站
杂物间
新版博客
关于 快刀切草莓君
友情链接
妙妙屋开发日志
注册
登录
搜索
文章列表
分类 标签
归档
# 基于图的多知识源迭代抽取 **20/11 COLING** Improving Commonsense Question Answering by Graph-based Iterative Retrieval over Multiple Knowledge Sources 问题:commonsenseQA 中的一些问题仅靠 ConceptNet 无法解决,e.g. *James was looking for a good place to buy farmland. Where might he look? A: midwest B: countryside C: estate D: farming areas E: illinois* 思路:通过基于图的迭代获取方式,从多个知识源获取知识来解决。 ## 1 模型架构 如下图,论文中的模型包含四个模块。 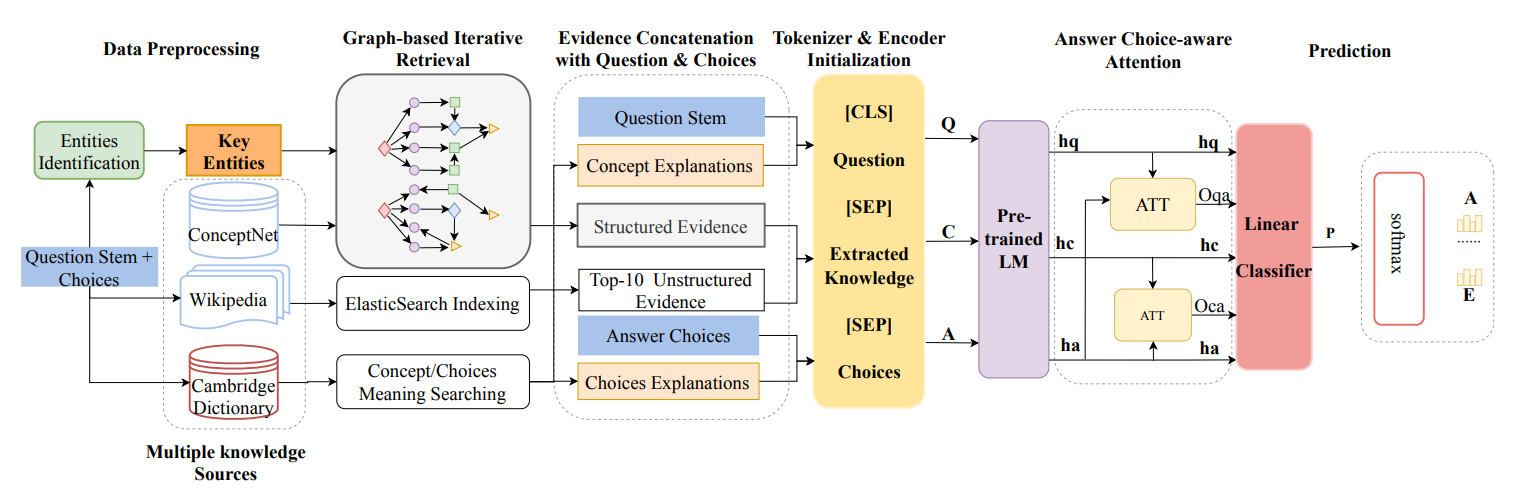 1. 基于图的迭代获取模块:从 ConceptNet, Wikipedia, Cambridge Dictionary 中取出相关知识。 2. 基于预训练模型的编码器模块:对知识 和 QA对 编码,问题和选项都包含额外的词典解释。 3. 关注答案选项的注意力机制 (answer choice-aware attention mechanism):计算知识在问题和选项上的注意力分数。 4. 预测模块 ## 2 基于图的知识迭代获取 1. ConceptNet - question concept 和 key entities (含选项中的实体) 作为初始化节点 - 根据问题的类型 (where, what),用规则的方式推断可能的关系,如此用迭代的方式来取回知识要素。 2. Wikipedia - documents 切分成 sentences,使用 ES 检索 (Elastic Search) 建立索引,用原始问题取出相关的 top10 句子。 - 对于无结构的文档文本,将文档的各个成分 (title, paragraphs, sentences) 作为节点,并…… (尚未理解) 3. Cambridge Dictionary - 引入实体或概念的解释,问题概念和实体。 - 将字典条目视作节点,从这些每个节点的例子或代名词中寻找关系。(只选择相关词的解释) 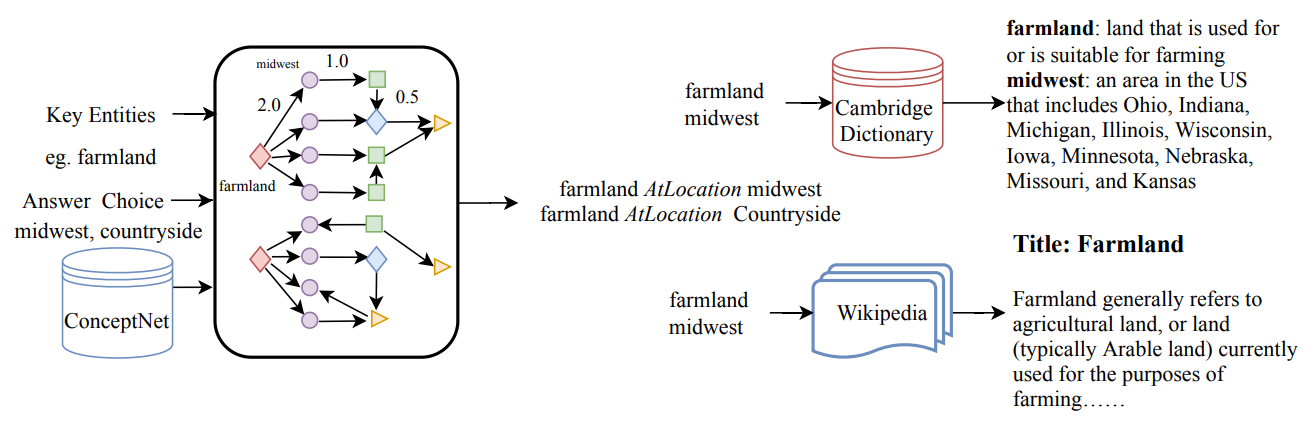 用 STS-B 上精调的 BERT 来对上述三种知识源取回的知识进行打分,选择 top 10 相关的知识进行后续编码。 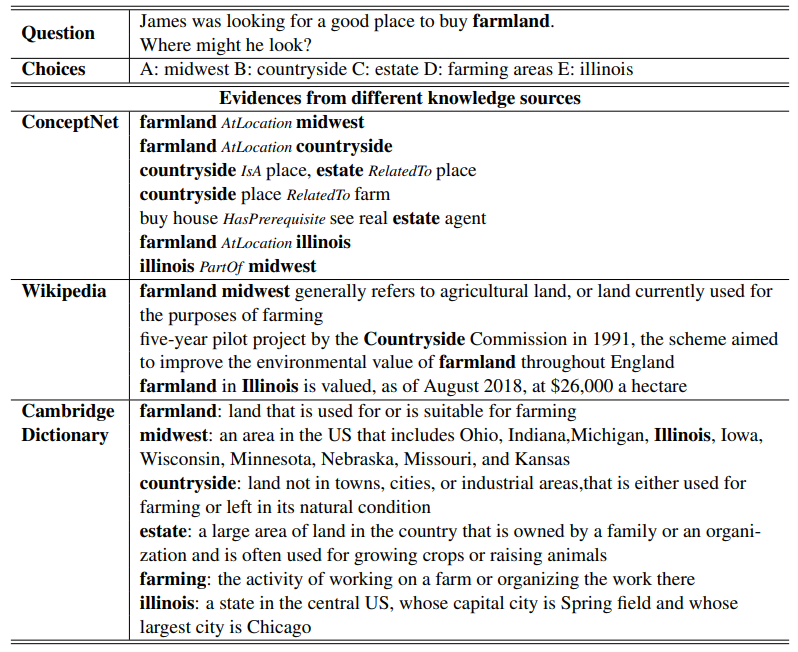 ## 3 预训练模型编码 Q:问题 + 问题中词干的解释;A:选项 + 选项的解释;C:上一步取得的知识。 使用 RoBERTa 进行编码,取最后一层的隐状态作为文本编码。 ## 4 关注答案选项的注意力机制 将上一步得到的 $$h_a$$ 和 $$h_c, h_q$$ 分别做 attention 得到注意力分数 $$O_{ca}$$, $$O_{qa}$$。 ## 5 预测 将上一步得到的注意力分数和3中的隐状态拼接,过一个 Linear,然后拿去预测。 <img src="https://i.loli.net/2020/12/07/af1TAvEVpI8SDdu.png" alt="image-20201207195046595" style="zoom:67%;" /> 不解:[seq_len, hidden] -> Linear -> [1, hidden] -> softmax -> [1]
文章信息
标题:基于图的多知识源迭代抽取
作者:快刀切草莓君
分类:自然语言处理
发布时间:2020年12月11日
最近编辑:2020年12月11日
浏览量:1352
↑