Toggle navigation
Mr.Strawberry's House
文章
网址导航
更多
甜品站
杂物间
新版博客
关于 快刀切草莓君
友情链接
妙妙屋开发日志
注册
登录
搜索
文章列表
分类 标签
归档
# Attention & Transformer seq2seq; attention; self-attention; transformer; ## 1 注意力机制在NLP上的发展 1. Seq2Seq,Encoder,Decoder <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915150904207-1559743524.png" alt="image-20200915094229730" style="zoom:50%;" /> 2. 引入Attention,Decoder上对输入的各个词施加不同的注意力 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151000395-1692673463.png" alt="image-20200915093758556" style="zoom:50%;" /> 3. Self-attention,Transformer,完全基于自注意力机制 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151018032-824250322.png" alt="image-20200915094135383" style="zoom: 67%;" /> 4. Bert,双向Transformer,mask 5. XLNet,自回归语言模型,自动编码语言模型,摒弃遮盖 ## 2 注意力机制 以机器翻译为例;Seq2Seq架构; ### 2.1 RNN + RNN 1. Encoder处理输入序列,得到上下文CONTEXT(一个向量,代表源文信息);Decoder处理CONTEXT逐项生成输出序列。 2. RNN在每个时间步接收两个输入 - 隐状态:上一个时间步传递来的;Decoder的初始隐状态为编码阶段的最后一个隐状态 - 词向量输入:Encoder为输入序列的对应位置的词向量;Decoder为上一个时间步的输出(第一个时间步的输入为Start) 3. 上下文向量定长,模型难处理长句 ### 2.2 RNN+RNN+Attention 1. Encoder 向 Decoder 传递更多的数据,不止传递编码阶段的最后一个隐藏状态,而是传递所有隐藏状态。 2. Decoder增加额外步骤,根据隐状态之间的相关性对不同的隐藏状态打分 - 为每个编码器隐状态打分;softmax加权;求和  - 打分后的Encoder隐状态加权后与当前Decoder隐状态结合,作为当前时间步的隐状态输入 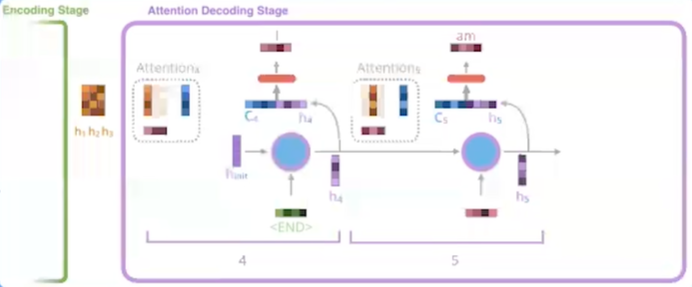 - Decode 过程中不同的步骤回关注于不同 Encoder 的隐状态 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151138424-1456084970.png" alt="image-20200915101128928" style="zoom: 67%;" /> ## 3 Transformer Attention Is All You Need; self-attention; ### 3.1 概述 - 仍然由encoder和Decoder组成,完全基于自注意力机制,不使用RNN。 - 编码器和解码器都是一组编码/解码组件组成,原论文使用了6个 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151217566-1507275943.png" alt="image-20200915132658479" style="zoom: 67%;" /> ### 3.2 Encoder 解码器 - 编码器由两个子层:自注意力层(见3.3节)、全连接神经网络 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151233336-106612772.png" alt="image-20200915133309916" style="zoom: 67%;" /> - 每个编码器组件结构相同,但不共享权重。 ### 3.3 自注意力机制 **自注意力机制全景图** 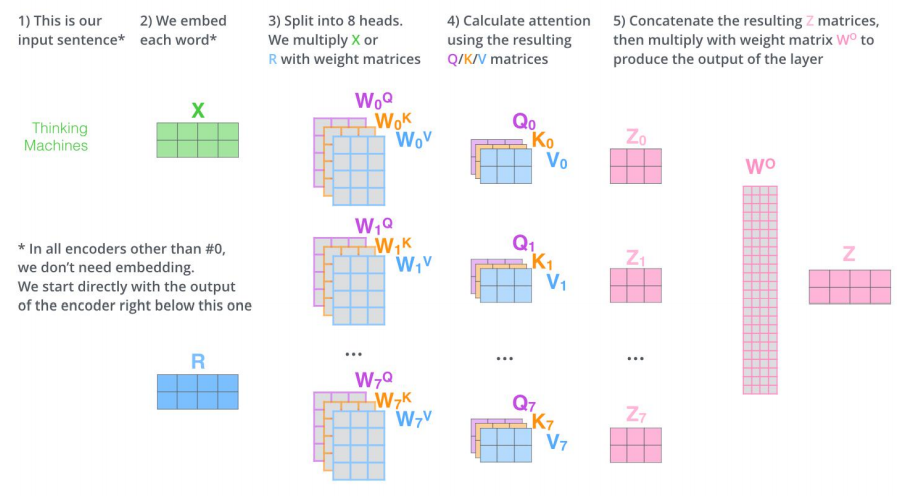 1. 词嵌入 word embedding - 发生在最底部的编码器;输入数据[batch_size, word_embedding_size, seq_len];完成嵌入后作为输入经过编码器;每个位置的词**并行**经过编码器,速度比RNN快。 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151406448-1720305791.png" alt="image-20200915134438789" style="zoom:50%;" /> - 并行运算未考虑到顺序关系,通过位置编码(positional encoding)使词嵌入包含位置信息。 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151711767-765791826.png" alt="image-20200915141816592" style="zoom:80%;" /> - 位置编码方式:sin、cos 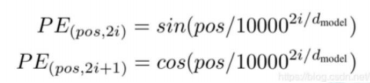 2. 自注意力计算 1. 三个参数W($W^Q$, $W^K$,$W^V$)与输入的向量相乘得到:查询向量q,键向量k,值向量v;新向量维度小于嵌入向量的维数 2. 对于**一个输入向量**,将其q向量与其他词的k向量相乘计算分数;分数高则关系密切 3. 将分数缩放(避免梯度弥散);通过softmax操作转化为概率。 4. 将每个词的v向量用上一步的softmax概率加权求和;得到该输入向量的 z值 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151750250-349753488.png" alt="image-20200915135415802" style="zoom:67%;" /> 5. 234步骤 以矩阵的形式,对多个输入向量并行求z,得到Z矩阵 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151811389-887399491.png" alt="image-20200915140326166" style="zoom:67%;" /> 3. 多头机制 - 为关注曾提供了多个表示子空间;拓展了模型专注于不同层面的能力 - 有多组qkv的权重矩阵;e.g. 使用8个关注头则每个编码器解码器会得到8组Z - 将所有的Z连接起来和一个权重矩阵$W^O$相乘,得到捕捉了所有注意力头的Z矩阵,再将其输入到接下来的全连接层。 ### 3.4 Decoder 解码器 1. 结构:自注意力,encoder-decoder attention,全连接层 2. 自注意力层:仅对输出序列中之前的位置;在softmax之前,把将来生成的位置设置为-inf 3. encoder-decoder attention - 在自注意力层、全连接神经网络之间加入了一个encoder和decoder之间的注意力层,类似seq2seqRNN模型中的注意力。 - 最后一个Encoder的输出,转换为K和V的集合,每个decoder在其encoder-decoder attention层中使用这些KV。 - 工作方式与多头注意力类似,区别在于是从Encoder Stack的输出中获取KV。 4. 经过N层decoder,最终的输出通过线性层和softmax层得到输出的词 <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151843118-2013133258.png" style="zoom: 80%;" /> ### 3.5 细节补充 - 残差和归一化 解码器编码器都有 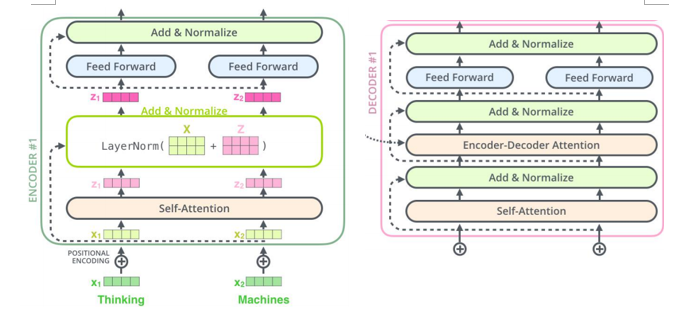 - <img src="https://img2020.cnblogs.com/blog/1403725/202009/1403725-20200915151927242-1236662684.png" alt="image-20200915144157226" style="zoom: 80%;" />
文章信息
标题:Attention & Transformer
作者:快刀切草莓君
分类:机器学习
发布时间:2020年9月16日
最近编辑:2020年9月16日
浏览量:1445
↑